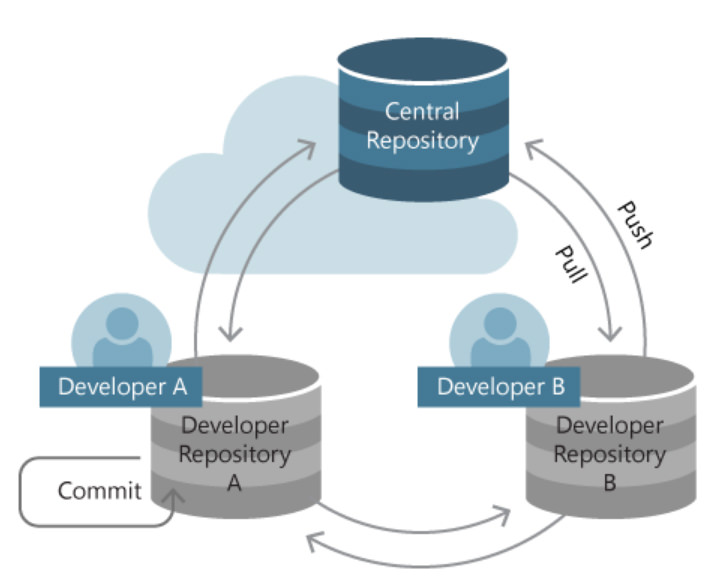
Initialize center and local repository
1
2
3
4
5
6
7
8
9
10
11init from scratch
git init <local_dir>
for central repository without working directory, use --bare
git init --bare <local_dir>
clone from GitHub, can just clone a subdirectory. pull all the remote branches. set up "main" branch to track "origin/main".
git clone <remote_repo> <remote_dir>
pull from other local repository
git remote add <remote_repo> <remote_address>
git pull # only pull the default branch
git pull <remote_repo> <remote_branch> # pull is equal to fetch and merge
git fetch <remote_repo> <remote_branch>Configuration
1
2
3
4
5
6git config --global user.name $name
git config --global user.email $email
git config --global credential.helper store
git config --global alias.$alias-name $git-command
git config --system core.editor $editor # e.g., vim
git config --global --edit.git/configRepository-specific settings.~/.gitconfigUser-specific settings. This is where options set with the —global flag are stored./etc/gitconfigSystem-wide settings.Staged snapshot in the staging area
operations on tracked files:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19git add <file>
git add <dir>
git add . # add all the files in the current directory
git add * # add all the files and folders in the current directory
before using `git add .` or `git add *`, we can exclude the untracked files in `.gitignore` (e.g., `*.<ext>`, `<dir>/`, use `!<file>` for exception).
git rm <file> # delete the file
git rm --cached <file> # untrack the file
git mv <old name> <new name> # mv = rm+add
git restore --staged <file> # move staged changes to unstaged changes
git restore <file> # remove unstaged changes
clear the entire staging area
git reset HEAD # move all staged changes to unstaged changes
git reset --hard HEAD # remove all staged and unstaged changes
Commit the staged snapshot
1
2
3
4
5git commit -m "<message>" #new commit node
git commit --amend #old commit node
`-a` means staging all the changes of tracked files
git commit -a -m "<message>"
git commit -a --amendBranch
1
2
3
4
5
6
7
8git branch #list local branches
git branch -r # list remote branches
git branch -a # list both remote branches and local branches
git branch -vv # list local branches and their tracked remote branches
git branch -d <old_branch> #use -D enforce delete
git checkout <old_branch> #switch to branch $branch
git branch <new_branch> #create a new branch
git checkout -b <new_branch> #switch to a new branch $branch(a) Imaging there exists a hash table of
key:valuepairs with branch name as key and commit node as value. When checkout a new branch b1,b1:current-commit-codewill be stored in the hash table. When checkout an existing branch b1, you will reach the hashed commit code. In both cases, b1 (HEAD) will be used as the hash key for the next commit node, that is, when you commit next time,b1:new-commit-codewill be updated in the hash table.
(b) Another perspective is treating the branch name as a pointer to the commit node and each branch is a retrospective history dating back from that node, which is essentially the same as (a).When checkout to another branch, git status (staged or unstaged modifications) will be transferred to that branch. If there exists file conflicts (operations on common yet different files), checkout will be forbidden.
Besides
branch, users can also addtagto each commit node.
1
2
3
4
5
6
7
8
9
10
11assume the current branch is master
merge: merge experiment into master
master moves one step forward, both experiment and original master are its parents
git merge experiment
assume the current branch is experiment
rebase: base experiment on master
duplicate the nodes between C2 and experiment after master, move experiment to up-to-date
git rebase master
in the simple fast-forward case, assume <branch> is ahead of <branch1>
then, `merge <branch1> <branch2>` and `rebase <branch1> <branch2>` work the same, just move <branch1> to <branch2>.
whereas, `merge <branch2> <branch1>` or `rebase <branch2> <branch1>` are not allowed.Tracking changes
1
2
3
4
5
6
7
8
9
10git status
git log #commit history
git log -n <limit> --stat
git log --all --graph --oneline # show the tree structure of all branches
git log --grep="<pattern>"
git log --author="John Smith" -p hello.py
git diff #view unstaged modification
git diff --cached #view staged modification
git diff <branch1>..<branch2>
git diff <repo>/<branch1>..<branch2>when using
git log, it will only show the ancestral commit nodes of current node.Date back to history
1
2
3
4
5
6
7
8
9
10
11revert the operations in <commit> and add one commit node ahead of HEAD
revert does not work on file
git revert <commit>
go back to <commit>
git checkout <commit> <file> is just copying the <file> in <commit>
git checkout <commit>
git reset <commit> changes branch name, working directory, and staged index
git reset <file> is removing the staged file
git reset --mixed <commit> #default, save the working directory
git reset --soft <commit> #save both working directory and staged index
git reset --hard <commit> #save none, dangerous!(a) For reset file, there are no options
--hardand--soft.
(b) For reset commit, afterreset --mixedorreset --hard, there are no staged snapshots. Afterreset --soft, staged snapshots enable the staged index to remain the same. More specifically, at the time before or afterreset --soft, if you rungit commit, the generated commit node should be the same.
Communicate with remote repositories
1
2
3
4
5
6
7
8
9git remote -v #list remote repositories
git remote add <remote_repo> <remote_address>
git branch -r #list the fetched branches of remote repositories
git fetch <repo> # fetch all of the remote branches
git fetch <repo> <remote_branch>:<local_branch>
git checkout -b <new_branch> <repo>/<remote_branch> # Checking out a local copy of specific branch
git pull <repo> <remote_branch>:<local_branch>
git push <origin> <local_branch>:<remote_branch>after merging code to address the conflict, use
git commit -a -m "$message", thengit push.git pullis equal to agit fetchfollowed by agit merge.Clean working directory
1
2
3git clean -f/d #clean untracked files/directory
git clean -f $path #clean untracked files in $path
`git clean` is often used togther with `git reset —hard`Stashing
If you are working in your repository, and your workflow is interrupted by another project, you can save the current state of your repository (the working directory and the staging index) in the Git stash. When you are ready to start working where you left off, you can restore the stashed repository state. Note that doing a stash gives you a clean working directory, and leaves you at the last commit.
1
2
3
4git stash save # stash the current state
git stash list # see what is in the Git stash:
git stash apply # return your stashed state to the working directory
git stash pop # return your stashed state to the working directory and delete it from the stashNote the commit-tree grows. “git log” prints the path from root to current node. “leave behind” prints the path from current node to the first common ancestor between current node and new node. Detached head will be off any branch, so create a new branch for the detached head.
Tips:
checkoutandresetwork on both file and commit with different meanings and usages, whilerevertonly works on commit.resetis often used for cancelling uncommited changes whilerevertis often used for cancelling commited changes.- Compared with
reset,checkoutandrevertfocus on the modification, so they are forbidden in many cases.
Github User:
- create a repository on GitHub
- create a local folder
git initgit remote add <remote_repo> <remote_address>git pull <remote_repo> <remote_branch>git push --set-upstream <remote_repo> <remote_branch>- add files
git add *git commit -m "msg"git push
Resources:
A good Chinese tutorial for git is here.
A good English tutorial for git is here.