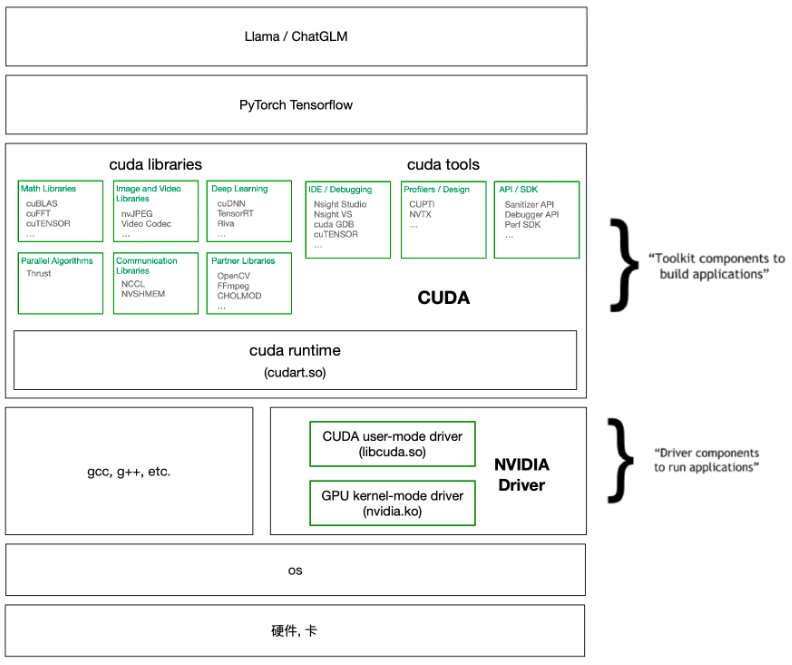
GPU Cuda and CuDNN
GPU
look up GPU information:
lspciorlshw -C displayNVIDIA system management interface, monitor GPU usage:
nvidia-smi(GPU driver version and CUDA user-mode version)
GPU Driver
check the latest driver information on http://www.nvidia.com/Download/index.aspx. Then, look up driver information on local machine:
cat /proc/driver/nvidia/versioncheck the compatibility between CUDA runtime version and driver version: https://docs.nvidia.com/deploy/cuda-compatibility/
Install NVIDIA GPU driver using GUI: Software & Updates -> Additional Drivers
Install NVIDIA GPU driver using apt-get
1
2
3sudo add-apt-repository ppa:Ubuntu-x-swat/x-updates
sudo apt-get update
sudo apt-get install nvidia-current nvidia-current-modaliases nvidia-settingsInstall NVIDIA GPU driver using *.run file downloaded from http://www.nvidia.com/Download/index.aspx
- Hit CTRL+ALT+F1 and login using your credentials.
- Stop your current X server session by typing
sudo service lightdm stop - Enter runlevel 3 by typing
sudo init 3and install your *.run file. - You might be required to reboot when the installation finishes. If not, run
sudo service lightdm startorsudo start lightdmto start your X server again.
CUDA
When using anaconda to install deep learning platform, sometimes it is unnecessary to install CUDA by yourself.
Preprocessing
- uninstall the GPU driver first:
sudo /usr/bin/nvidia-uninstallorsudo apt-get remove --purge nvidia*andsudo apt-get autoremove;sudo reboot - blacklist nouveau: add “blacklist nouveau” and “options nouveau modeset=0” at the end of /etc/modprobe.d/blacklist.conf;
sudo update-initramfs -u;sudo reboot - Stop your current X server session:
sudo service lightdm stop
- uninstall the GPU driver first:
Install Cuda
Download the *.run file from NVIDIA website
- The latest version: https://developer.nvidia.com/cuda-downloads
All versions: https://developer.nvidia.com/cuda-toolkit-archive
1
sudo sh cuda_10.0.130_410.48_linux.run
and then add into PATH and LD_LIBRARY_PATH
1
2
3echo 'export PATH=/usr/local/cuda/bin:$PATH' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc
source ~/.bashrc
check Cuda version after installation:
nvcc -V. Compile and run the cuda samples.
CuDNN
CuDNN is to accelerate Cuda, from https://developer.nvidia.com/rdp/form/cudnn-download-survey, just download compressed package.
1 | cd $CUDNN_PATH |



